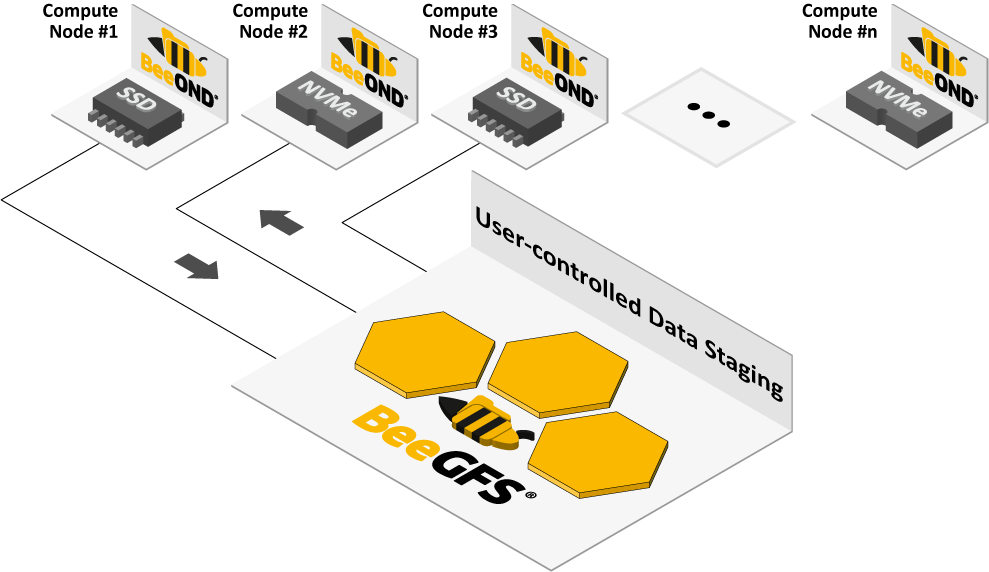
Maximise your Data with BeeOND
BeeOND is designed to integrate seamlessly with cluster batch systems. It creates temporary parallel file system instances on a per-job basis using the internal SSDs or NVMe drives of the compute nodes allocated to a job.
With BeeOND:
- Efficient Instance Creation: It swiftly creates BeeGFS instances for diverse applications.
- Enhanced Performance: Boosts job performance by using internal storage.
- Compatibility and Transfer: Works with any cluster file system for smooth data transfer.
- Seamless Integration: Integrates easily with workload managers like Torque and Slurm.
- Utilize hardware you’ve paid for: BeeOND allows you to utilize the hardware you’ve already paid for by turning local compute node storage into high-performance parallel scratch space.
Such BeeOND instances do not only provide a very fast and easy to use temporary buffer but can also keep a lot of I/O load for temporary or random-access files away from the global cluster storage. Increasing the proficiency of the client nodes by adding such functionality will speed up critical projects enormously.
Under our BeeGFS Community License Agreement, BeeOND may be used free of charge with up to five compute nodes contributing storage.
For production use of BeeOND, or deployments exceeding five storage-contributing nodes, please reach out to our sales team (sales(@)thinkparq.com) or one of our authorized partners.