by Peter Braam, CTO, ThinkParQ, January 2021
Welcome to the BeeGFS blog. I intend to occasionally publish some of our architectural thoughts, specifically to solicit feedback, publicly in blog comments or on our mailing list. Alternatively you can send an email to cto <at> thinkparq <dot> com. Probably we’ll find that posts here will be most useful during our early consideration of features, and perhaps there will be 2-4 posts per year.
Many partners ask about managing data across collections of servers in their clusters. For example, how can data be rebalanced over emptier, new servers and fuller, old servers? Technically we use the word pool, e.g. old pool and new pool, to refer to the available storage on the older and newer servers. There are variations on this question, for example, how can we leverage servers with NVMe drives that form a fast storage tier? Here the word tier is another technical term designating a collection of storage services. Utilizing tiers means that we want to move files to that tier to have them ready for fast transfer to clients and move them back to a pool on a slower tier when they have been idle for some time and merely consume capacity on the expensive, fast devices. In yet another scenario we would want to move files that have not been accessed for some time, or that belong to a finished project into an S3 object store.
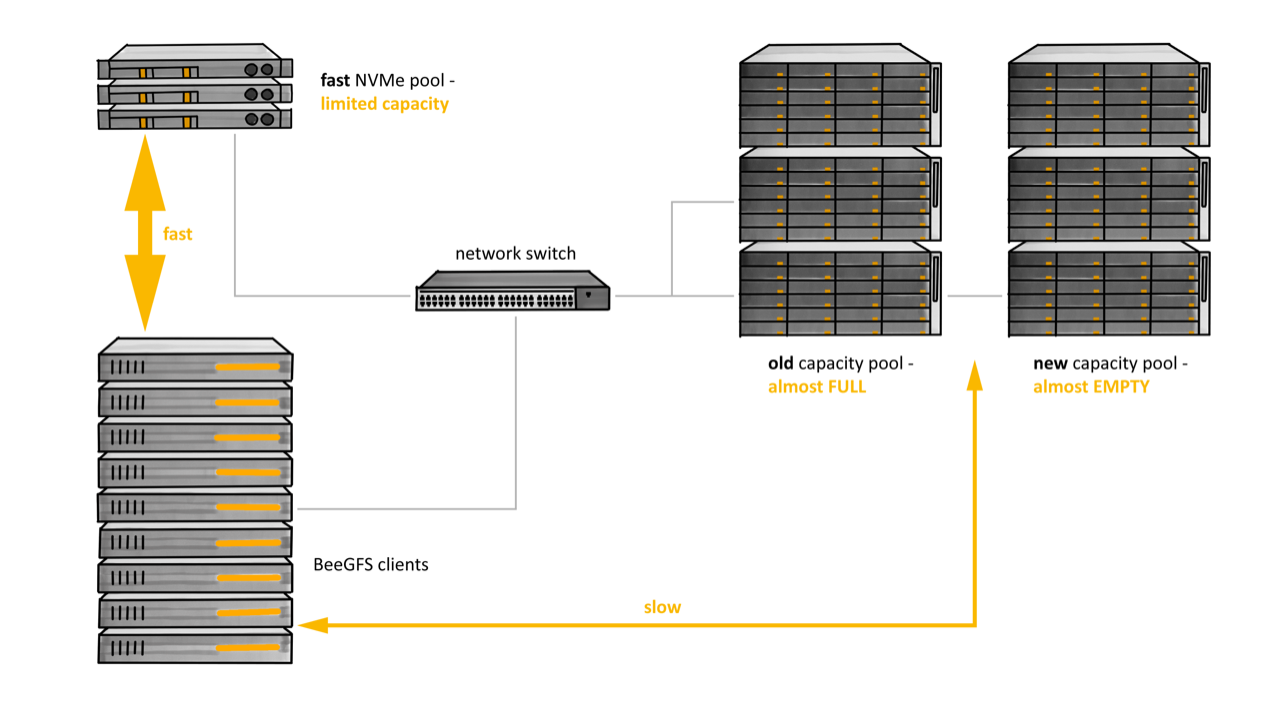
Figure 1: BeeGFS cluster requiring space rebalancing and fast tier management
During discussions with our partners, several other features were requested and we began to see how closely related they are. The following features appear to be at the top of the wishlist:
- handling tiers – placing or moving data into faster or slower tiers
- data rebalancing – within and between pools
- data movement – parallel data movement within, into, and out of BeeGFS
- feeds into Irods, S3-like object storage, HSM systems, and auditing systems
- directory subtree quotas
ThinkParQ prefers to keep the BeeGFS file system fast, nimble, and easy to use, and in this spirit, the architecture proposed here combines minor features in the file system with a few external utilities, some of which exist as open source software or can be derived from it.
Consider the following file system interfaces and external utilities:
- BeeGFS event logging – including read-only file access and quota events
- Atomically swap the data between two BeeGFS files
- Block or abort concurrent writes on a single file
- A powerful data-movement tool, like Los Alamos’ pftool
- A sub-tree aware file system inventory database
- Directory quota management through client file system directory tree
In this blog post, we are going to briefly discuss these interfaces and utilities and see how they will enable the features above.
Let’s start with a summary. All of the feature requests share a common requirement, namely having knowledge about collections of files. Such knowledge can be extracted from the existing BeeGFS event log which provides file access and modification events on a socket, in real-time, on a file by file basis. For historical knowledge about larger collections of files, we will use a subtree-aware inventory database. Below, we will illustrate what these databases can do and how they are maintained. Most of the features under discussion involve data movement and we include a powerful parallel file moving tool as one of the desirable utilities.
Now, let’s look at the additional logic to provide the core functionality of the features.
If we want to exploit a fast tier dynamically, a dynamic-fast-tier (DFT) utility should observe the event log to detect common access patterns. For example, it can anticipate that an application is going to iterate through all the files in a directory when it sees that a few have already been opened. 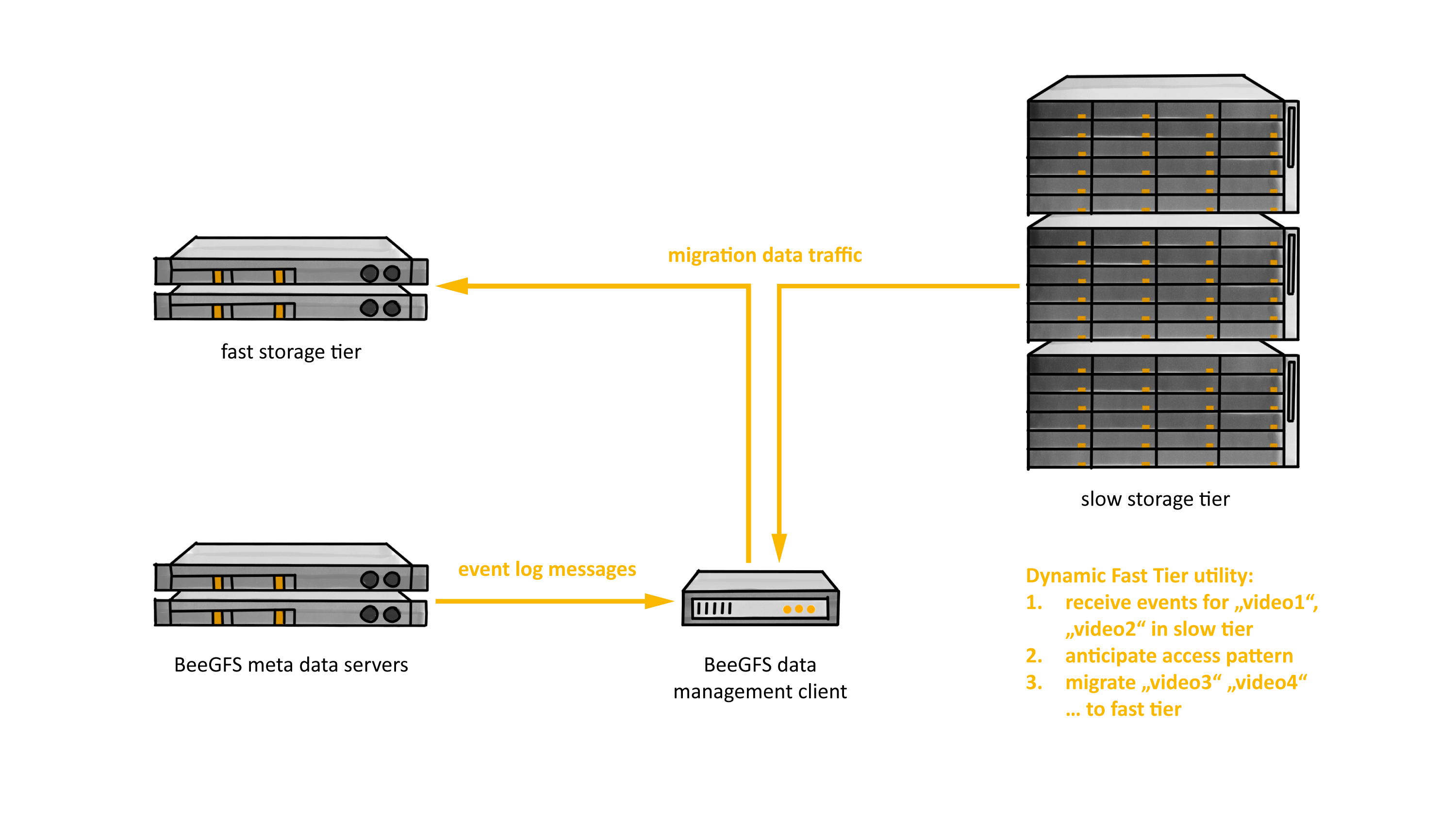
Figure 2: event log and dynamic adaptation for fast tiers
When the DFT utility observes such a pattern, it will invoke the data mover to copy the file to a faster tier. LANL has created a sophisticated parallel data mover called pftool, which carefully manages work queues across a collection of data mover nodes and includes interfaces that can perform I/O with object stores. We will see below why a powerful utility will be useful.
But there is a subtlety, and just copying the file to the fast tier isn’t quite enough. During this copy operation, we may want to abort the copy or block concurrent writes to the file by another process. This is necessary to keep the data migration process consistent, and it is not a complicated feature. We simply abort our copy when another process opens the migrating file for writing. When the copy is done, the original file should point to the data on the new tier. A convenient interface for this is to swap the data in the original and copied file, which is a quick metadata-only operation. After this, we can delete the inode to which we copied, which now has the data on the old tier.
Is it reasonable to expect that these relatively simple interfaces and a copy tool can give a reasonable solution to the tiering problem?
The other requested features are similar in spirit, and most are somewhat simpler than the tiering problem we just discussed. One difference to note is that in many cases the event logging system cannot provide the right stream of filenames upon which to act. This is where an inventory database comes into play.
We want the inventory database to record for each directory and for a set of conditions (predicates) the number of and aggregate bytes consumed by the files which satisfy the condition in the subtree of that directory. When we introduce no condition at all we record the file count and bytes in the subtree of each directory. This is already quite useful because it gives a snapshot of the sub-tree quota (often called directory quota). A near instantaneous lookup will produce these numbers, which are normally obtained by a run of a utility like “du”.
Another condition might state that the file must reside on the fast tier of storage. For this condition we record the count of and bytes consumed by files on that tier in the subtree of each directory, allowing us to see how full the tier is and initiate migration from it. Alternatively, we can look at files accessed or modified before or after a certain date, or by files owned by a particular user or group. If extended attributes are used, additional user managed predicates can be leveraged as well. In fact, tracking storage location in BeeGFS is done with extended attributes. Figure 3 illustrates how the directory summaries that we record in the inventory add up what is in their subtree.
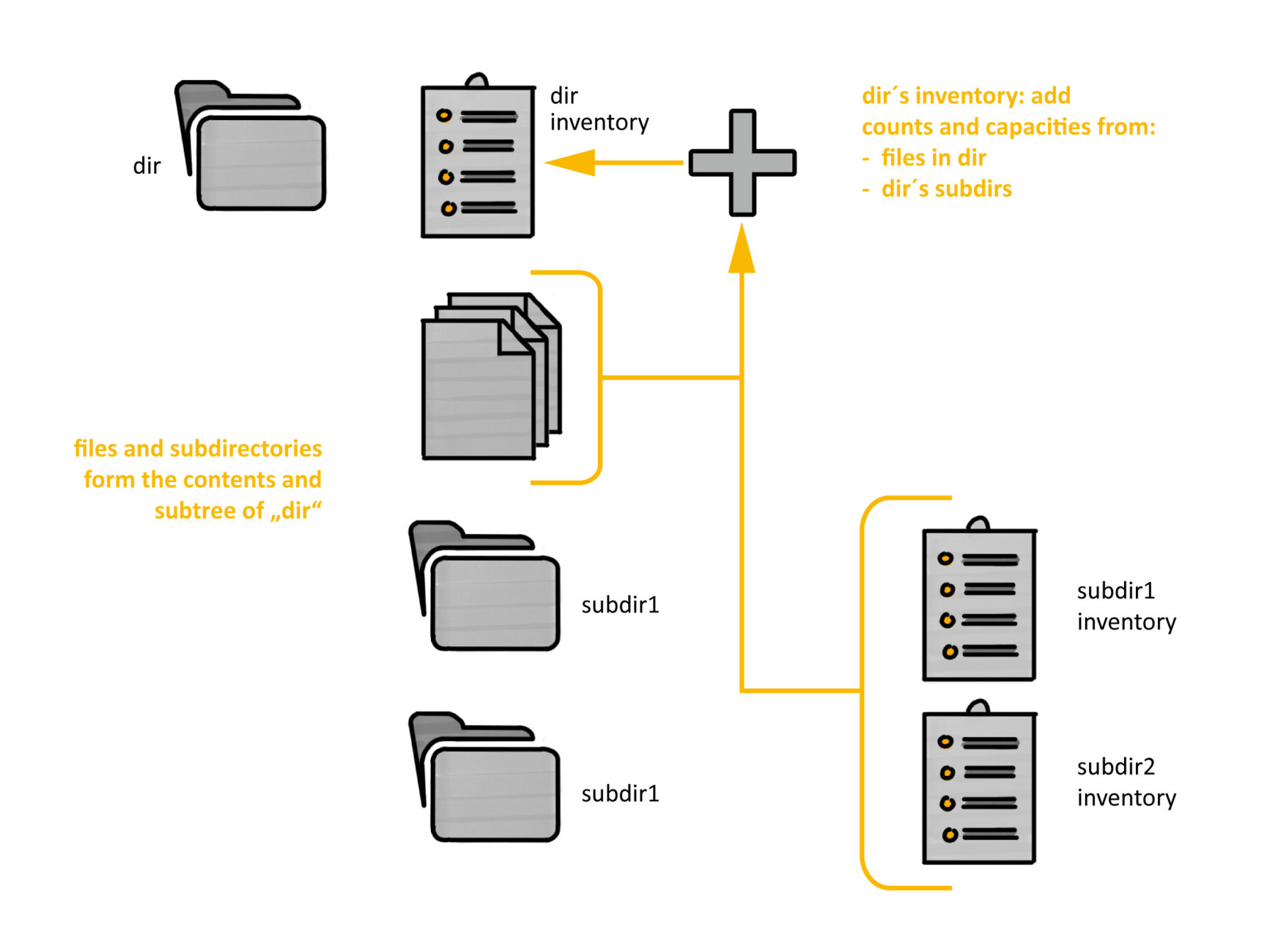 Figure 3: Subtree inventory database records add up file counts and bytes consumed by files in every subtree satisfying a property
Figure 3: Subtree inventory database records add up file counts and bytes consumed by files in every subtree satisfying a property
But before discussing the database further, let’s see how we can implement a directory quota system and the other features mentioned above.
A possible way to enforce directory quota is to introduce two extended attributes for directories subject to directory quota. One is the administrators choice of the maximum allowed quota, and the other attribute contains the consumed quota derived from the inventory database. Enforcement can proceed, for example, by not allowing files under the directory to be opened for writing when the consumed quota exceeds the maximum quota (for rigorous enforcement quota changes arising from already opened files must be discussed also, which we omit from the discussion here). The BeeGFS client file system can enforce this in the open system call with modest overhead. I would traverse from the file that is being opened to the ancestor in the dentry tree that has the quota attributes. When a user encounters such a denial to open a file, and when it subsequently removes some files to free up some space, the client could create a file system event which is consumed by a directory-quota (DQ) utility. The DQ utility updates the inventory database and resets the quota consumed, and the user can try again.
The data movement cases for rebalancing pools, servers, and migration to and from the cloud or HSM mentioned above are simpler. A pool-rebalancing (PR) utility will use the following logic. Periodically after the inventory database has been updated, it queries the inventory to see if too much space is consumed in a particular pool. If that is the case, it uses the inventory to find directories (using a fast logarithmic search) in which candidate files for migration can be found. Note that a nice predicate for the search could select files that reside in the pool, are of reasonably large size, and haven’t been accessed too recently.
A common scenario for pool rebalancing is after servers have been added, and in this case perhaps many files have to be migrated. Here a powerful parallel file mover can maintain migration jobs evenly and efficiently across a set of mover nodes.
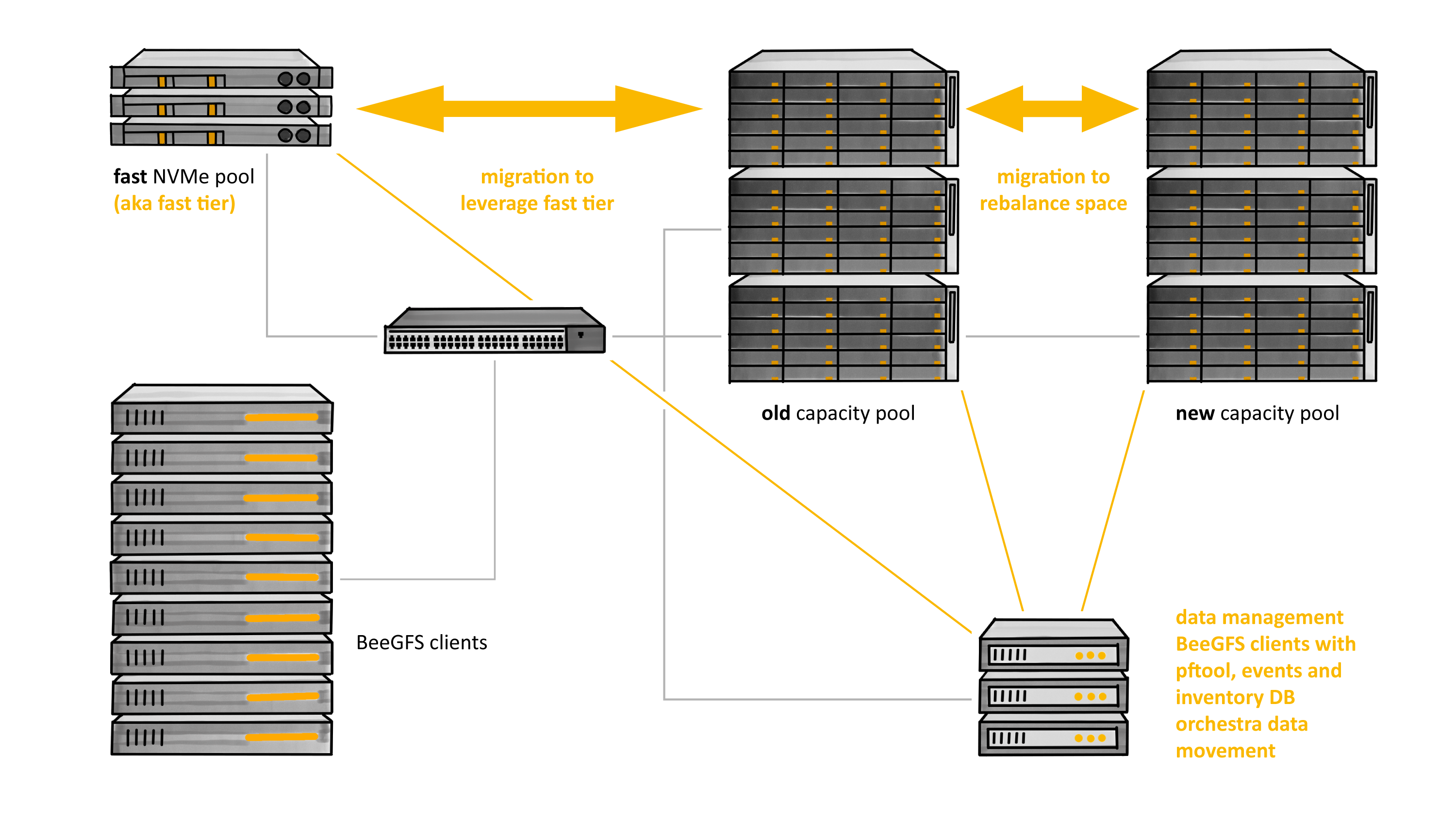 Figure 4: Space rebalancing and fast tier management with pftool, inventory, and events
Figure 4: Space rebalancing and fast tier management with pftool, inventory, and events
The use of an inventory database is not a new idea, it has been discussed as early as the 1990’s in academia, and falls in the general class of Merkel tree structures. More recently, Apple included some of these features in APFS, and Los Alamos’ grand unified file index (GUFI) was introduced in 2018 while perhaps the simplest inventory database was described at MSST in 2017. A key difference between the database we propose to use and an HSM database such as Robinhood is that there will only be entries for directories. There will be no database entries for every file, and this is a deliberate choice to keep the database much smaller than the file system metadata itself.
The creation of such a database requires a file system scan and one could propose to do this just occasionally at a low priority. However, the inventory database can often be updated very efficiently. Because the database has an additive structure, one can perform an update in a small sub-tree and propagate the changes to the root by adding them into ancestors. But even better, a database update can skip subtrees which were not accessed since the previous update. Particularly for interactive situations like we encountered for directory quota, there usually is a quick way to restore a user’s standing with respect to quota. If snapshots and differences between snapshots are available the updates to this database can be very efficient as they merely need to add and subtract counts and space used based on the differences.
The database will not be 100% accurate, and while that will not lead to any data loss, it will be possible to think of unlikely but unfortunate scenarios. For example, an out-of-date database may contain insufficiently many candidates to migrate out of a pool, because the pool was updated more recently than the database.
Surprisingly many features can be created without complex changes to the file system. We are excited about this possibility and curious if you see further applications or drawbacks.
Our next post will be about a very different topic, again driven by our users. We will explore how BeeOND, the much loved BeeGFS On Demand configuration tool can evolve further.
—
We value your feedback and comments, please comment below or on the BeeGFS User Forum.
Leave A Comment