How did we get here?
Where does BeeGFS need to go to support its users for years to come? What changes are needed to enable the next generation of AI and HPC workloads, not just today, but for the next decade and beyond? These are questions ThinkParQ and NetApp ask ourselves, our mutual customers, and the greater BeeGFS community almost obsessively.
We understand that users of parallel file systems and other large-scale storage solutions can’t make decisions lightly. So, we feel a mutual obligation to tread carefully, while still innovating boldly, in a rapidly changing IT landscape where just over a decade ago the cloud was still about as nebulous as the real thing. Luckily, ThinkParQ is no stranger to HPC, and NetApp is no stranger to enterprise storage.
The significant uptick in the adoption of AI and other HPC techniques in enterprises makes us ideal partners to anticipate how HPC storage must evolve to stay relevant and useful. Anticipating this trend is a big reason why back in 2019 ThinkParQ partnered with NetApp to deliver joint solutions built around BeeGFS.
Together, our engineering teams have worked to deliver innovation around BeeGFS in several ways, including introducing a shared-storage HA solution, bringing support for Kubernetes, and collaborating with NVIDIA to certify BeeGFS with NVIDIA DGX A100 systems for machine learning and deep learning (ML/DL) workloads at scale. This brings us to today, where we’re excited to share how NVIDIA Magnum IO GPUDirect Storage (GDS) now supports BeeGFS. As part of this, we created a number of enhancements, most notably the addition of multirail support (described in more detail below), along with some smaller improvements to the native cache mode and BeeGFS client networking stack that have far-reaching benefits to how BeeGFS filesystems can be architected going forward, regardless of whether GDS is in use.
Why is Magnum IO GPUDirect Storage important?
From a storage perspective, ML and DL workloads are not so dissimilar from many HPC workloads. They are characterized by many read operations and, particularly in the case of DL, result in the same data being reread multiple times. However, while traditionally these datasets were processed by CPUs, the types of algorithms and techniques commonly applied in modern ML and DL training are greatly accelerated by the use of GPUs. Of course the more ‘Moore’s law’ is applied to GPUs, the more simply moving mountainous amounts of data to and from the GPU becomes a bottleneck to the overall time to train.
Enter GPUDirect Storage. GDS enables direct memory access (DMA) between GPU memory and local or remote storage behind a NIC. It avoids the need to store and forward data through buffers in CPU memory and instead reads and writes data directly into GPU memory. If this sounds similar to the traditional benefits of remote direct memory access (RDMA), you’re spot on. In many ways, GDS extends RDMA capabilities to account for the existence of GPU memory.
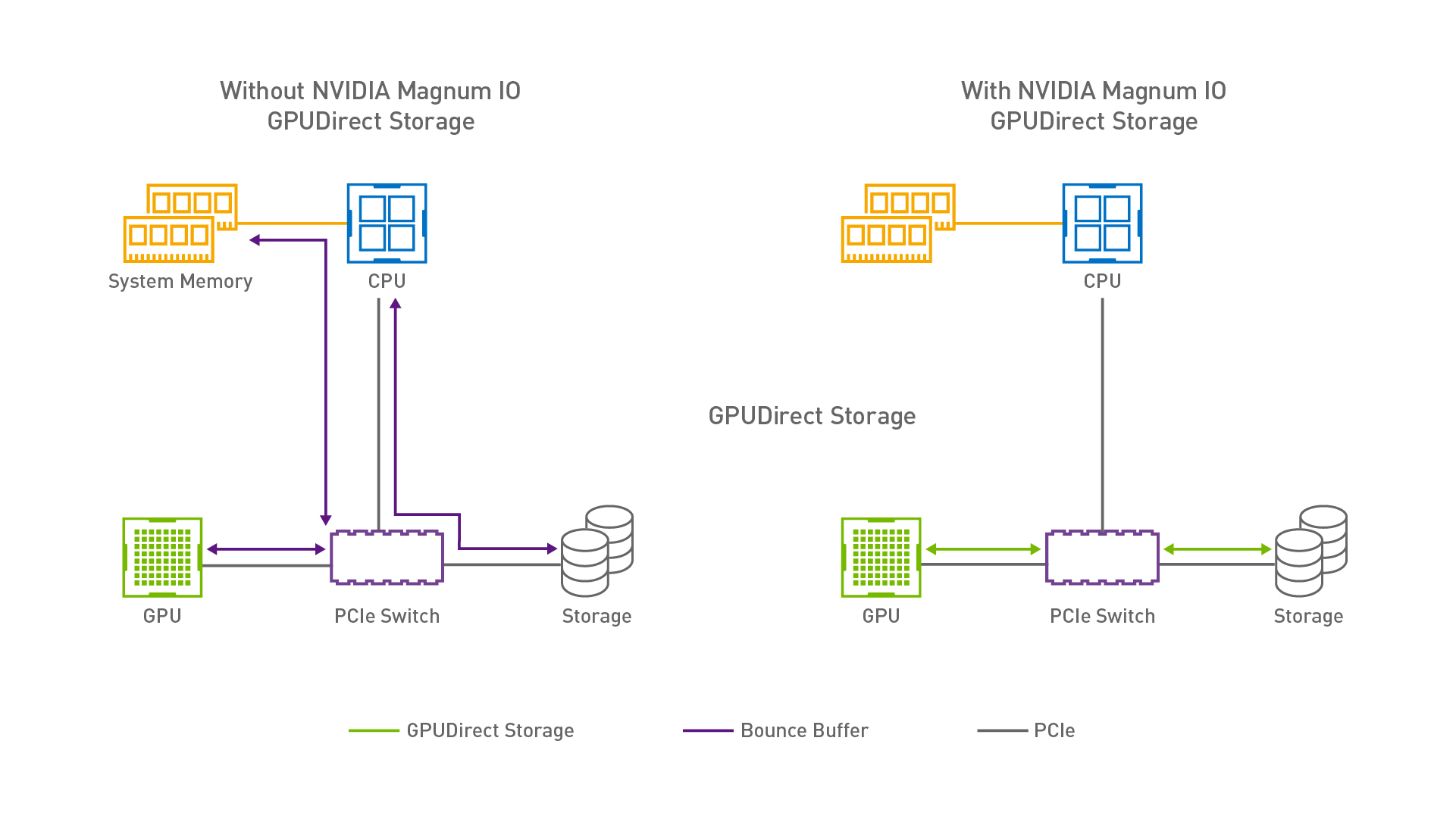
How does Magnum IO GPUDirect Storage work in general?
The traditional way of reading data into a GPU memory buffer involves reading into a CPU memory buffer, usually via the POSIX API, and then cudaMemCpy that buffer into GPU memory. This process increases latency and CPU load and decreases throughput from the filesystem to GPU memory.
To provide an alternative, lower overhead data path, GDS provides access to the GPU for DMA engines included in other PCIe devices, like NICs or NVMe drives. To make use of that functionality, applications, instead of using POSIX I/O, can choose to interface with the cuFile API which will relay the file I/O request through the nvidia-fs kernel module. This module is responsible for setting up the appropriate memory mappings, providing access to information about these mappings to other kernel drivers like the BeeGFS client module, and passing the I/O request on to the Linux kernel VFS.
How does Magnum IO GPUDirect Storage work in BeeGFS?
BeeGFS, like many other filesystems, uses the Linux kernel VFS as an abstraction layer to provide a standard interface to applications. Therefore, BeeGFS I/O functions will be called whenever the VFS receives an I/O request for a file stored on a mounted BeeGFS.
A GDS enabled BeeGFS module will register with the nvidia-fs module and will then be able to differentiate between traditional POSIX I/O requests and requests that have been relayed through nvidia-fs. While BeeGFS has been capable of RDMA data transfers before the introduction of GDS, the nature of the buffers and the mechanism to transfer the buffers over to the storage servers are quite different between the two.
Traditional POSIX I/O originates from user space and is usually issued by applications that are not RDMA-aware. Thus, the pages that hold the data that is to be transferred need to be copied into a kernel space buffer that can then be sent to the storage server via RDMA send. If a user space application wants to read data from BeeGFS and process it on a GPU, the data needs to be copied from an RDMA buffer in kernel space to a user space buffer and then needs to be copied to GPU memory again.
For GDS on the other hand, we want the storage servers to be able to directly read from or write to a buffer in GPU memory that is exposed via the DMA engine on the network interface. To make that possible, we added RDMA read and write functionality to the client and server-side code. RDMA transfers can now be set up with a client-to-server message that contains the necessary information like addresses and keys for the memory regions that are to be accessed by the storage server. After that setup is complete, the storage server can read from and write to those memory regions without any CPU involvement on the BeeGFS client side. Because the exposed buffers are located in GPU memory, applications that run on the GPU can access the data immediately before or after it is transferred. No copies on the client side are needed.
One more important prerequisite to achieving the best performance possible with GDS in BeeGFS was to support multirail networking. This means that the BeeGFS client can now be configured to use multiple RDMA capable network interfaces on the same network and can automatically balance traffic across those interfaces, based on how many connections are available and already active on each of the interfaces. The core multirail functionality is independent of the GDS implementation and nvidia-fs, so even clients that don’t use GDS can benefit from being able to use multiple RDMA- enabled network interfaces now. And when GDS is enabled, the BeeGFS client can call a function in nvidia-fs to determine which network device will provide the fastest path to a specific GPU, taking into account the PCIe topology in the node.
You keep saying it makes things “faster.” How much faster?
The benchmarking results for this blog post were collected using two NVIDIA DGX A100 systems connected using an NVIDIA Quantum 200Gb/s InfiniBand switch to a single second-generation NetApp BeeGFS building block. In this building block, two Lenovo SR665 servers were used to run BeeGFS management, metadata, and storage services configured in a Linux HA cluster, and block storage was provided by a pair of NetApp EF600 storage systems:
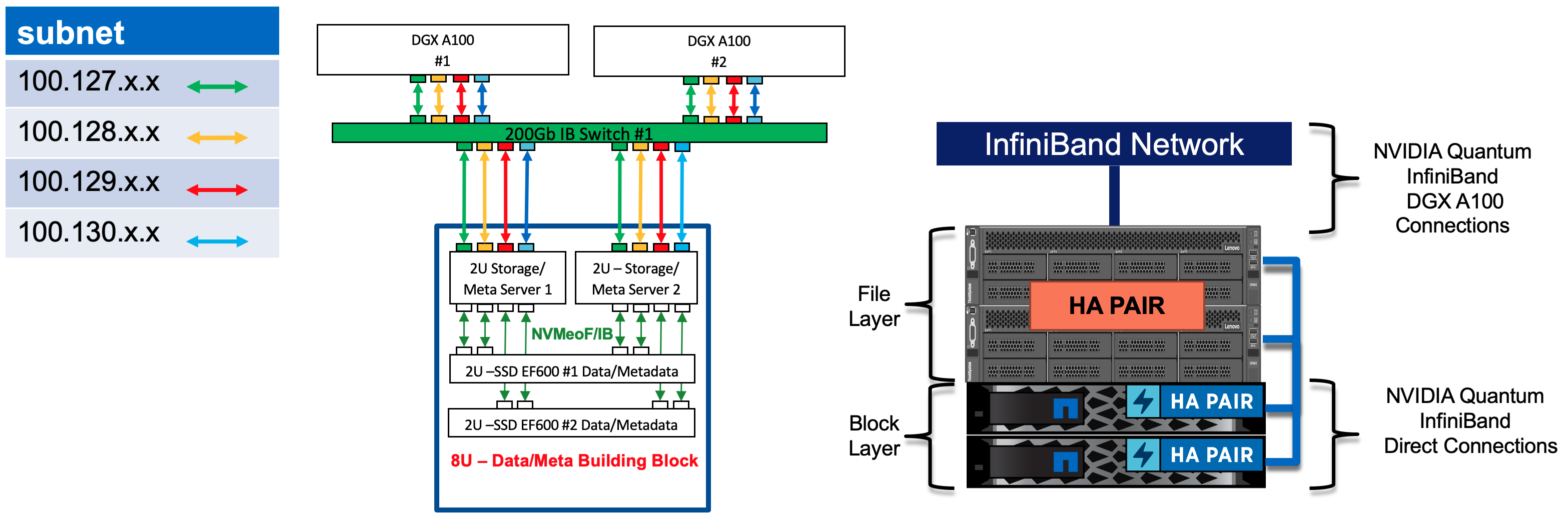
For this post, we intentionally focused on the relative performance boost GDS provides and did not try to showcase some very large numbers only attainable from a large BeeGFS file system or many GPU servers. Also note this configuration also did not take advantage of the new multirail support in BeeGFS, which would have simplified the deployment by reducing the number of required IPoIB subnets to just one.
Pictures are worth a thousand words, so I’ll leave you with this image showing read performance at various GPU counts and I/O sizes without GDS (blue bars) and with GDS (orange bars):
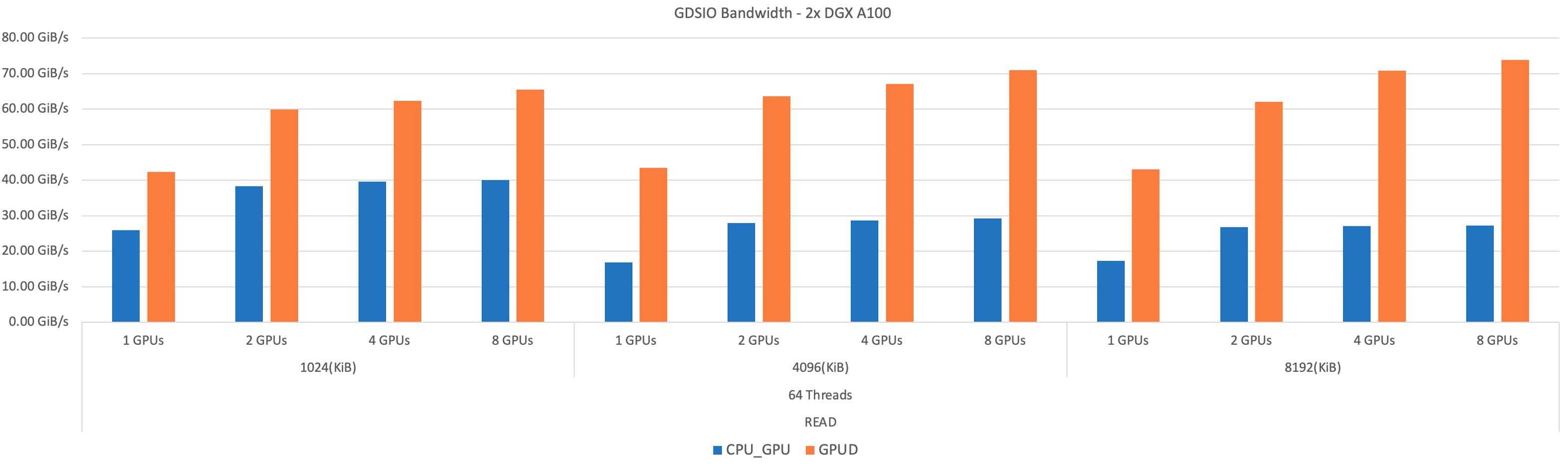
Okay, we have to make one comment, just think of how much less storage you’ll have to buy if you can get roughly double the performance from the same amount of hardware!
So what’s next?
If you couldn’t tell from the beginning of this post, we’re just getting warmed up. GDS is just one of the enhancements planned for BeeGFS as it evolves to meet the needs of supersized environments like the NVIDIA DGX platform, along with ARM support, enhancements to our caching capabilities/utilization, offering improved performance for AI, machine learning, and other HPC workloads.
Authors:
Philipp Falk, Head of Engineering, ThinkParQ
Joe McCormick, Software Engineer, NetApp
We value your feedback and comments, please comment below or on the BeeGFS User Forum.
18th March 2022